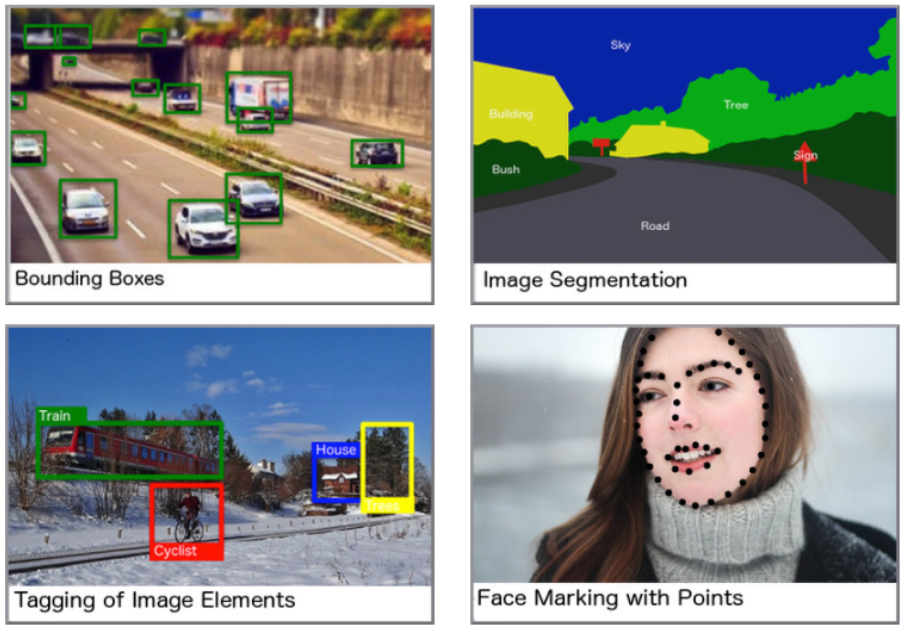
〔Data Labeling〕 사투리·국내 주요도로 등 AI 학습용 데이터 170종 개방(korea.kr) 과학기술정보통신부와 한국지능정보사회진흥원은 인공지능(AI) 허브(aihub.or.kr)를 통해 학습용 데이터 4억 8000만 건을 개방한다고 18일 밝혔다. 과기정통부는 지난 2017년부터 기업·연구자·개인 등이 시간 및 비용 문제로 개별 구축하기 어려운 인공지능 학습용 데이터를 구축·개방해왔다. 지난해부터는 디지털 뉴딜 ‘데이터 댐’ 구축 프로젝트의 일환으로 구축 규모를 대폭 확대해 추진 중이다. 인공지능 학습용 데이터는 인공지능 개발에 사용된다. 그동안 국내 인공지능 기업들은 인공지능 개발에 필요한 데이터 확보를 위해 해외 오픈데이터를 많이 활용해 왔다. 그러나 한국어, 국내 도로환경 등 국내..